Appearance
Optimizers in Deep Learning
by Bhadra, on 24/03/2025
Optimizers are mathematical functions or algorithms which lower the loss function by updating the model’s learnable parameters (weights and biases) in response to the output of the loss function.
In order to maximize the efficiency of production by minimizing losses, to improve the training speed and to get the most accurate output, we need to know how to adjust the learning rates, weights and biases of the neural network during each training epoch. Optimizers help us in doing precisely this.
DIFFERENT TYPES OF OPTIMIZER
Gradient Descent
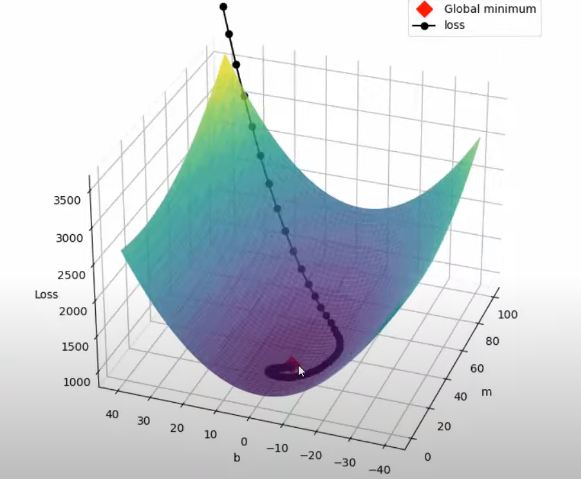
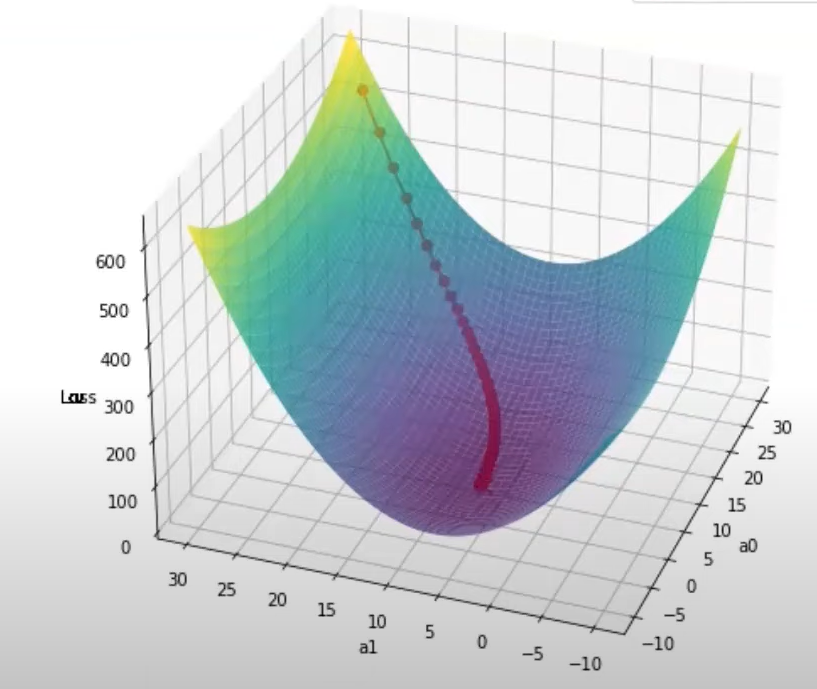
Gradient Descent is an iterative optimization algorithm in which we approach the local minima by taking steps in the negative direction of the gradient at that point .
In Gradient Descent, we first compute the gradient (slope) of the loss function at a given point. Then, we update the parameters by moving in the opposite direction of the gradient, ensuring that we minimize the loss and move toward the optimal solution.
Batch Gradient Descent(BGD)
In BGD, the gradient of the function is calculated using the entire training dataset
Despite guaranteeing convergence, this method can be slow and prone to getting stuck in local minima when dealing with non-convex models.
Stochastic Gradient Descent (SGD)
SGD calculates the gradient of the cost function using only one randomly chosen data point in each iteration. It updates the model's parameters based on this individual gradient.
Here,
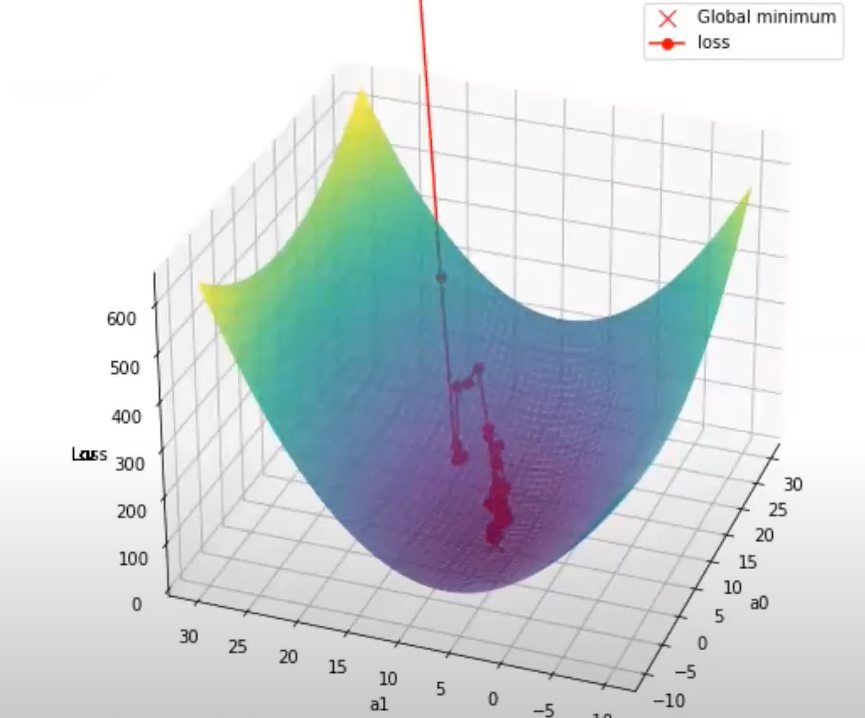
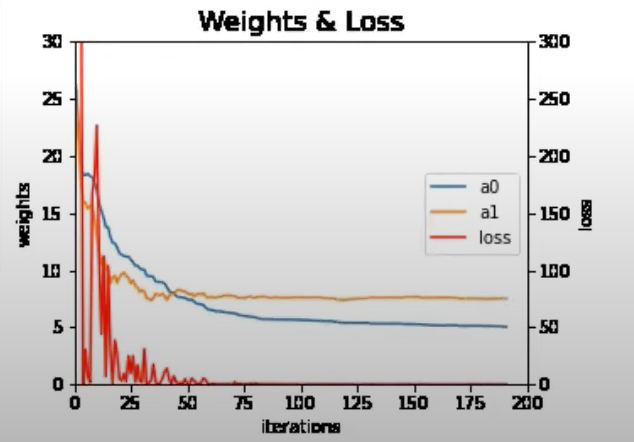
This method updates the gradient frequently but can make the training process very noisy(many fluctuations)
Mini Batch Gradient Descent (MBGD)
MBGD is a compromise between BGD and SGD. It calculates the gradient of the cost function using a small batch of randomly chosen data points in each iteration. It updates the model's parameters based on this batch gradient.
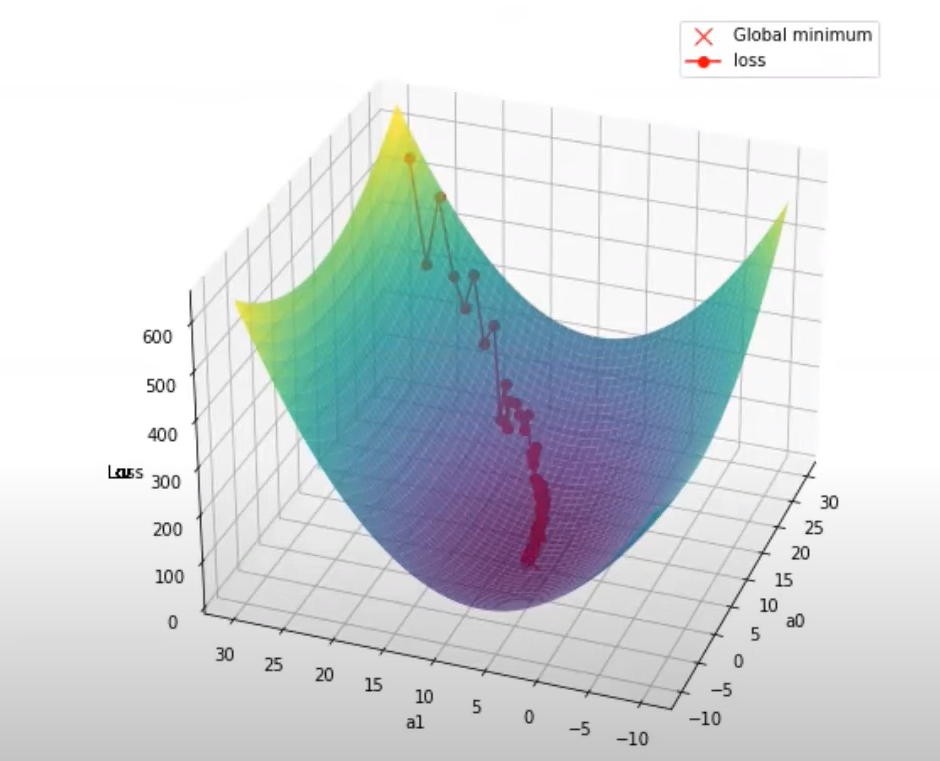
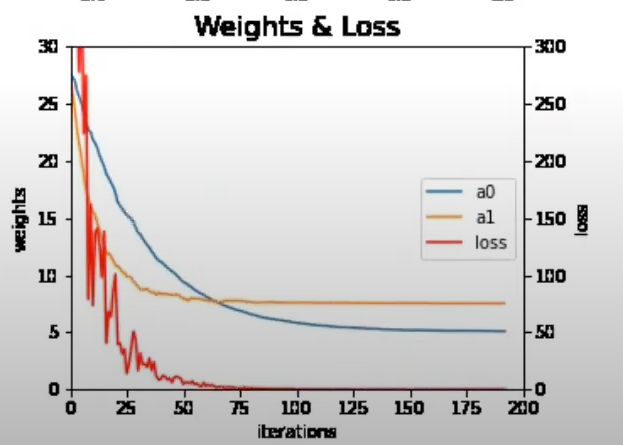
MBGD balances speed and stability, making it the most commonly used approach in deep learning.
Stochastic Gradient Descent with Momentum
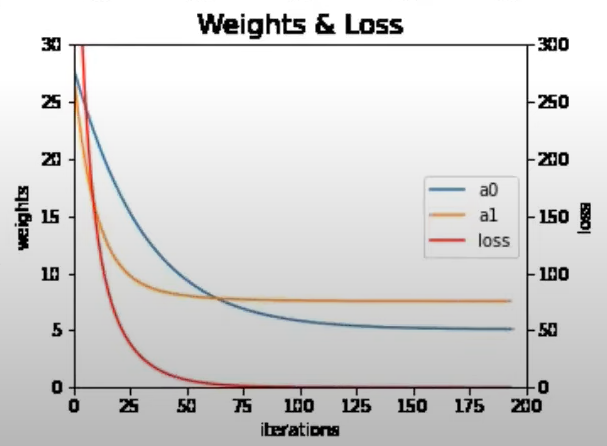
The path of learning in mini-batch gradient descent is zig-zag, and not straight. Thus, some time gets wasted in moving in a zig-zag direction. Momentum Optimizer in Deep Learning smooths out the zig-zag path and makes it much straighter, thus reducing the time taken to train the model.
When faced with non-convex curves (i.e complex loss functions), the stochastic gradient descent posed multiple challenges;
- High curvature: small radius can lead to a higher curvature. Non-convex optimizations as shown in the figure usually have large curvature, which cannot be easily traversed using SGD methods
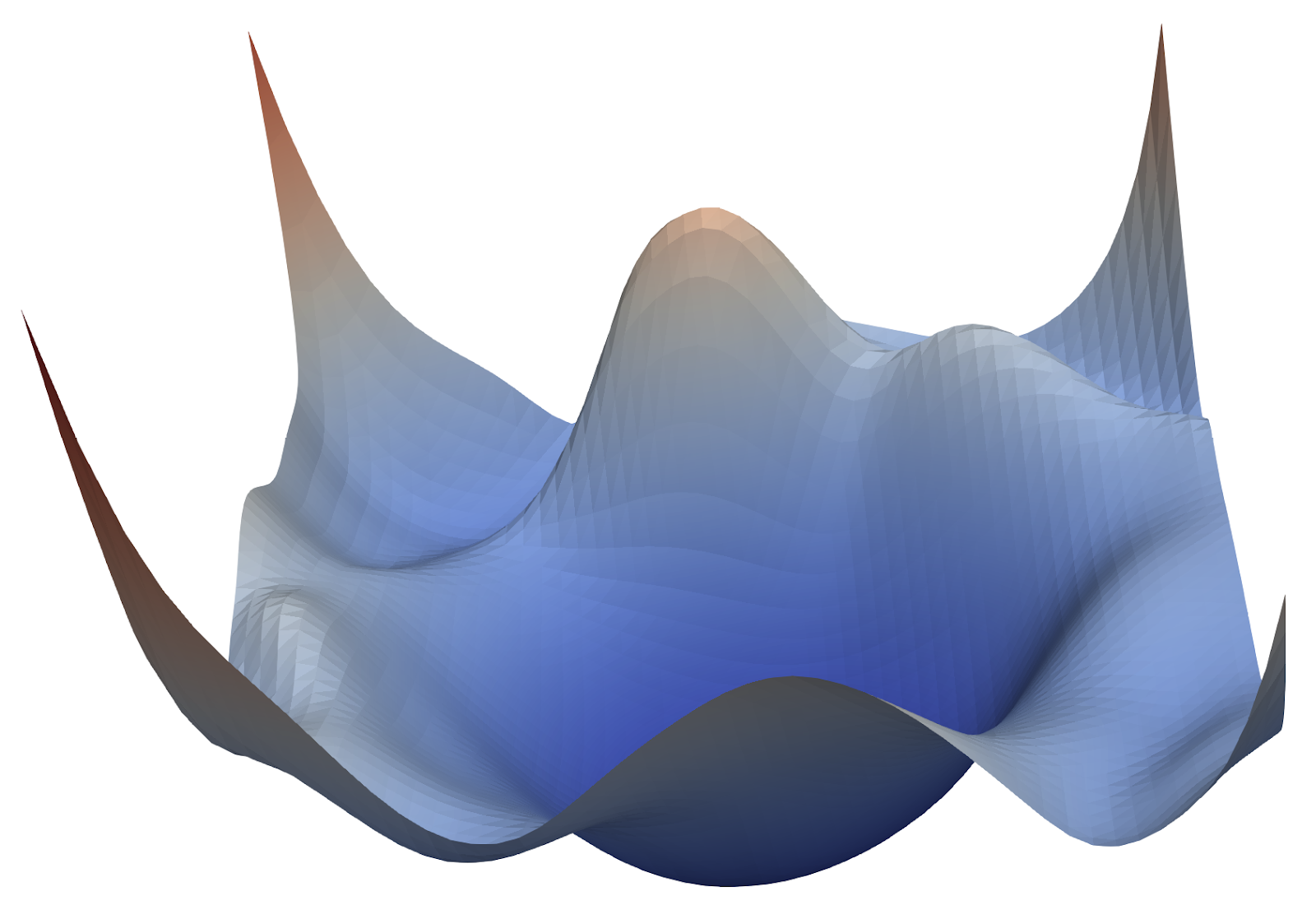
Consistent gradients: When the change in slope of the curve decreases, especially in case of saddle point, the gradients become more consistent, leading to smaller updates and consequently more learning time.
Noisy gradients: SGD usually follows a highly “noisy” (fluctuating) path which implies that it requires a more significant number of iterations to reach the optimal minimum.
Momentum simulates the inertia of an object when it is moving, that is, by adding a fraction of the previous update to the current one, it retains the “velocity” (direction and speed) of the gradient descent.
Mathematical representation:
The change in the weights is represented by:
Where,
: velocity of the gradient descent : gradient of the loss : momentum coefficient (usually between 0.5 and 0.99) : includes a fraction of the history of the velocities, helping it to utilise the past gradients.
The term
Since βis typically chosen in the range
This way we are using the history of velocity to calculate the momentum. This part provides acceleration to the formula.

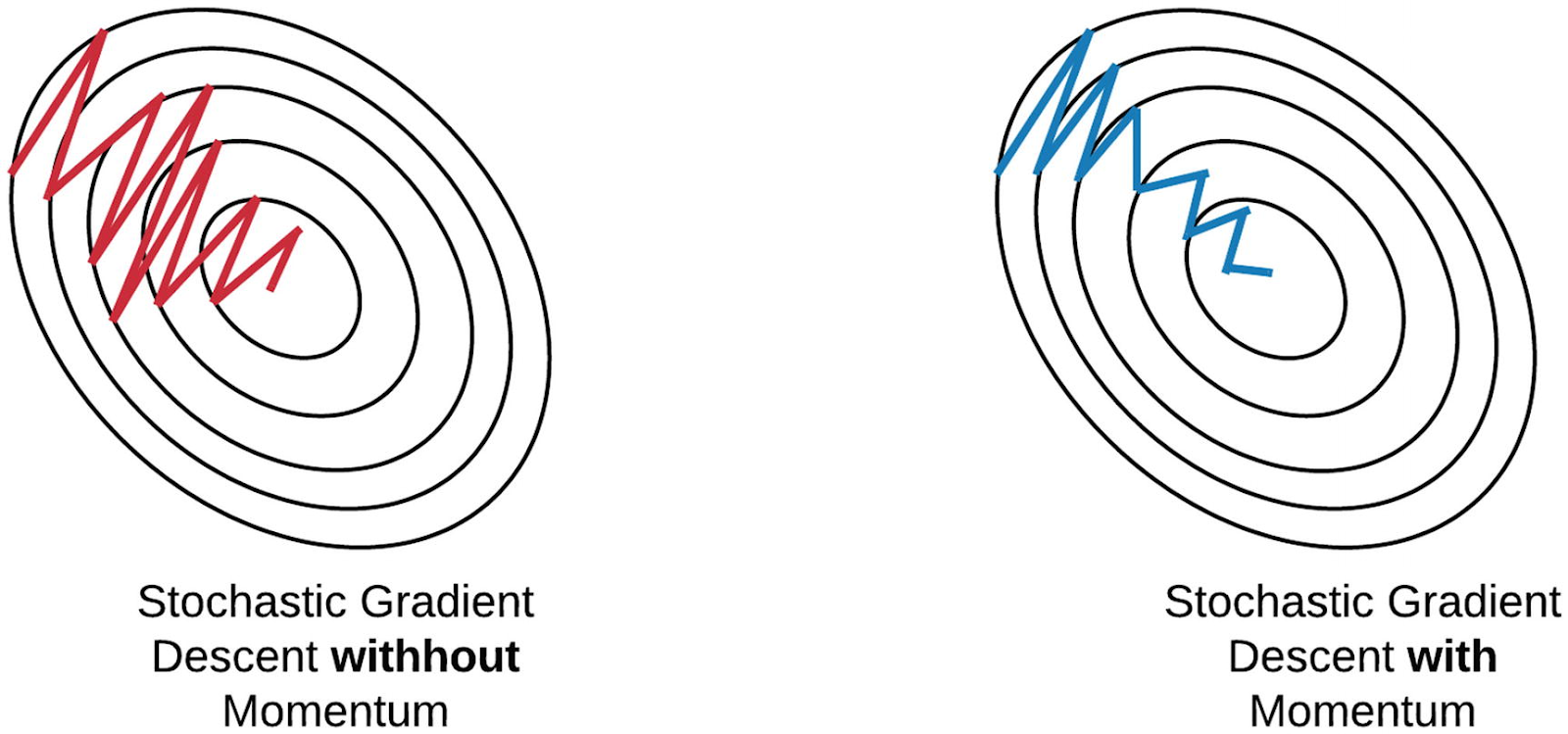
Disadvantages
If the momentum value is set too high, it can cause the optimization process to overshoot the optimal solution,potentially leading to poor accuracy and oscillations around the minimum.
The momentum value requires a critical hyperparameter that needs to be chosen manually and with precision to pervent overfitting or overshooting.
Nesterov’s Accelerated Gradient
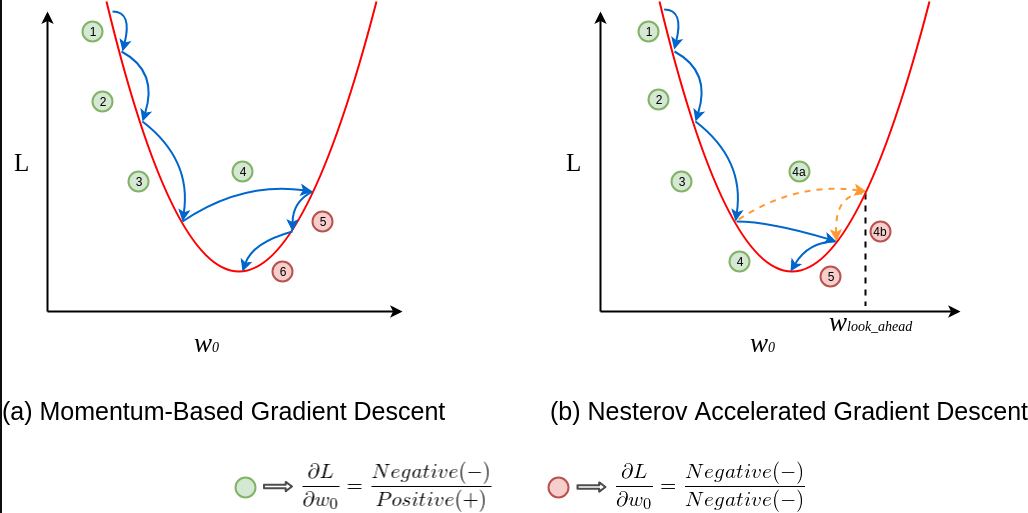
Nesterov’s Accelerated Gradient is a momentum based optimization technique that uses a "look ahead" method on the parameters to decide the gradient in order to prevent overshooting.
In the traditional momentum method, the current gradient and the weighted sum of the past updates is calculated simultaneously and then a big jump or update is made using this accumulated gradient or "velocity" term as explained previously.
In contrast to this, Nesterov's method breaks down the process into two steps: First, NAG takes a "look ahead" step based on the weighted sum of the past updates (momentum term). Secondly, it calculates the gradient at this new "look ahead" point and makes a correction by adjusting the update based on this.
This breaking down of steps helps in preventing overshooting, allowing for more controlled updates.
Mathematical representation:
- Calculating "look ahead term"
- Calculating gradient
- Updating the velocity term
- Update the weights
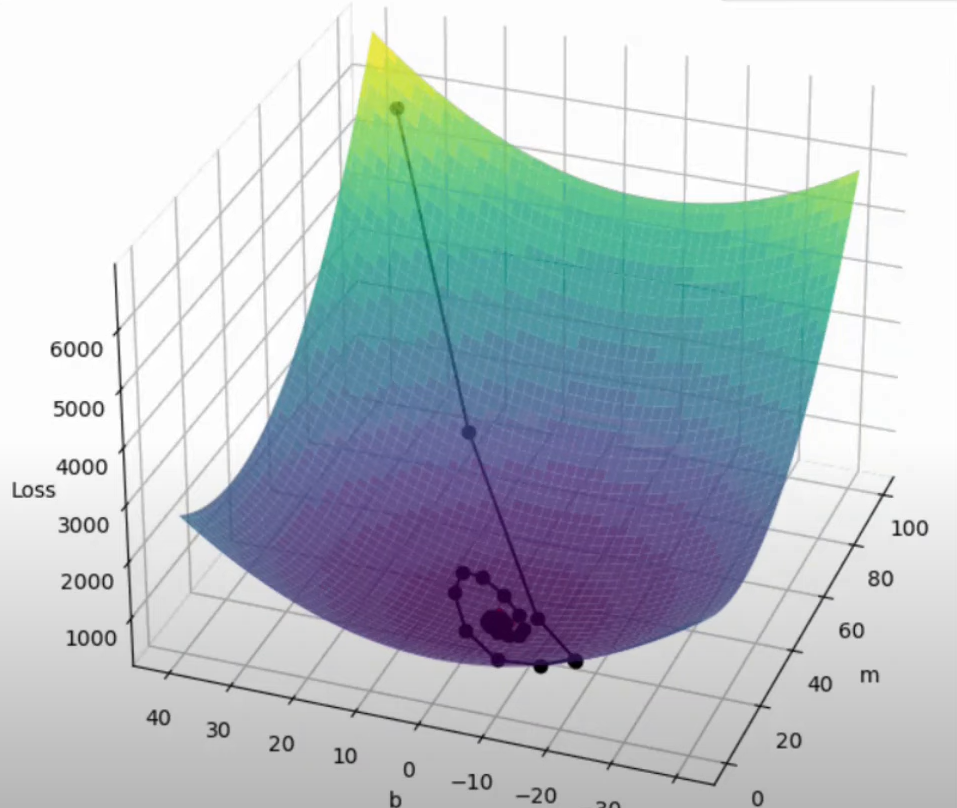
AdaGrad (Adaptive Gradient)
In the previous optimization techniques, we saw that the learning rate was kept constant (at around 0.01). However, this can pose problems when we deal with datasets where the majority of the data is sparse and only some are dense.
In order to solve this problem, AdaGrad uses different learning rates for different parameters.
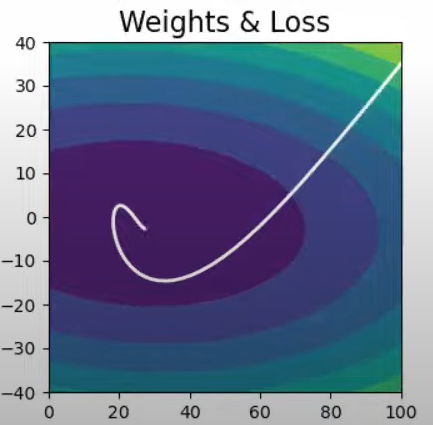
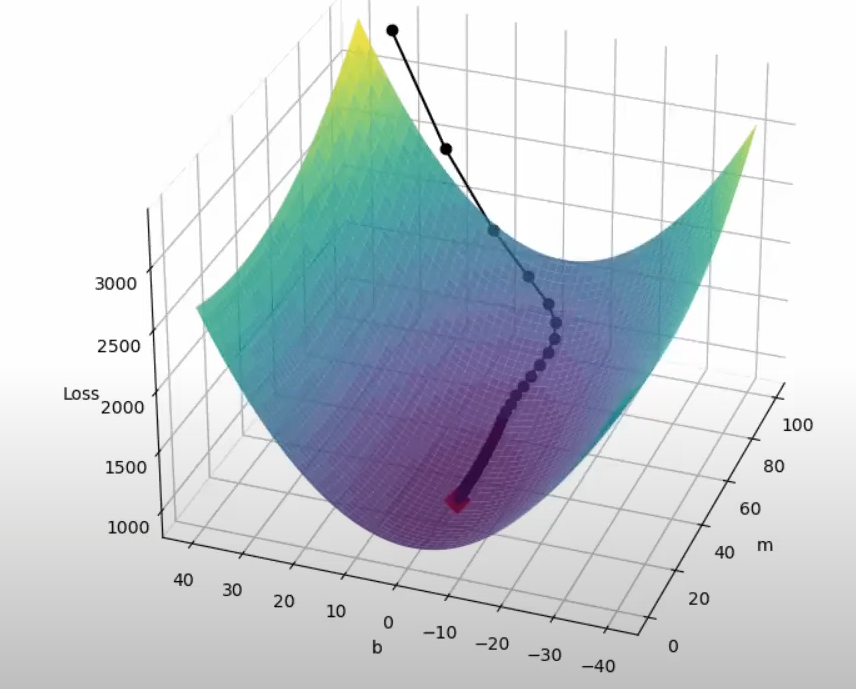
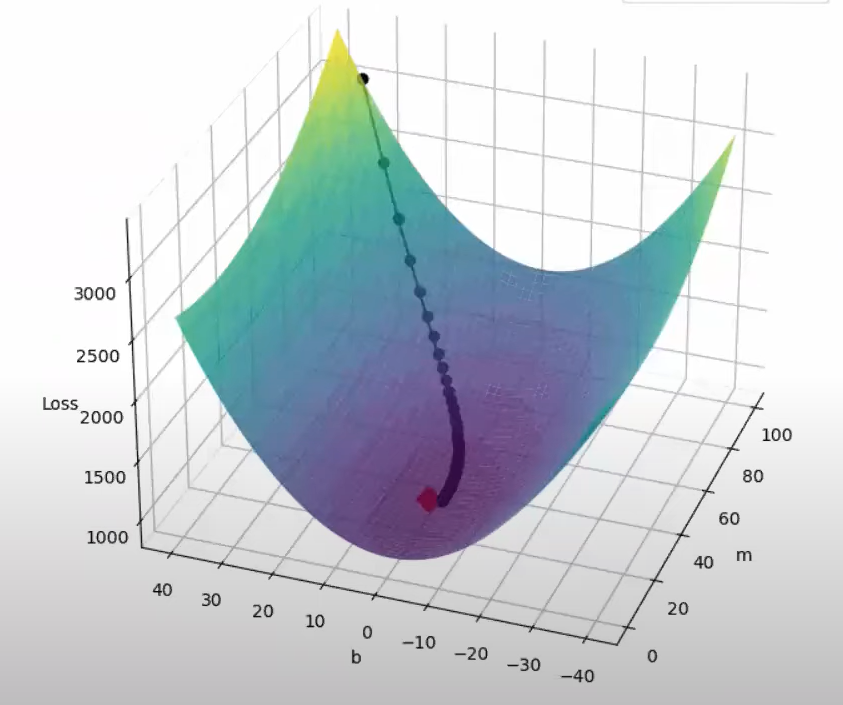
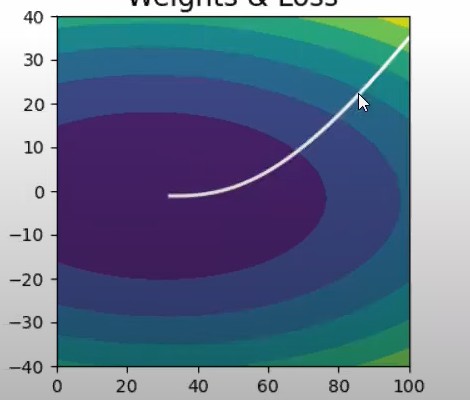
Both batch gradient descent and momentum optimization techniques do not work optimally in case of such data. As depicted in the images , the slope increases quickly in the direction of b(dense data) and then gradually decreases in the direction of m (sparse data)
As is evident from the images,neither of the optimizers are able to follow a more efficient path ,due to the fixed learning rates.
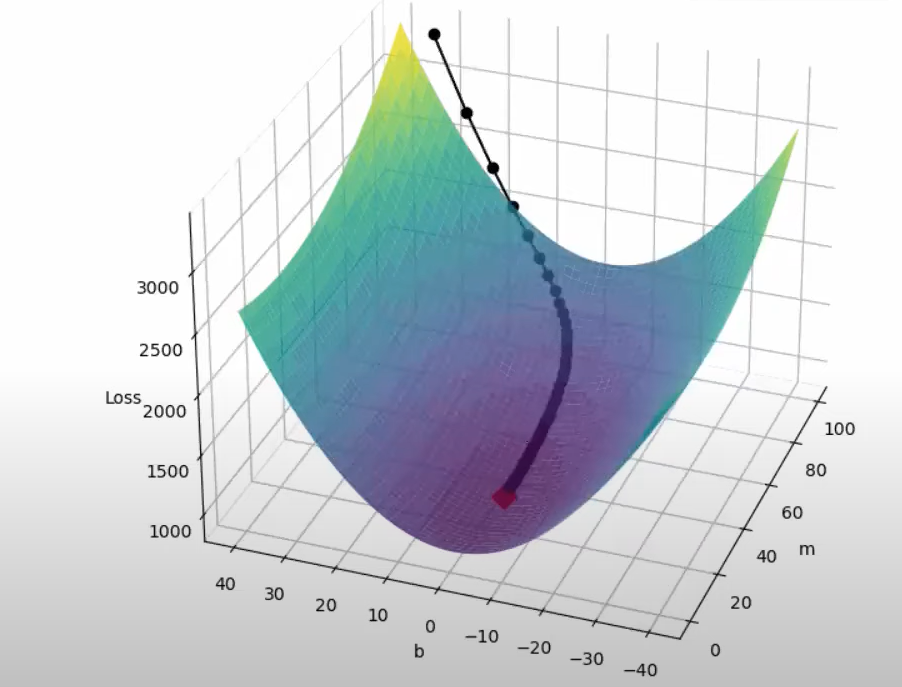
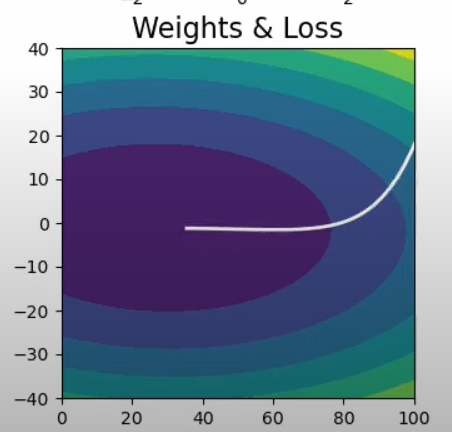
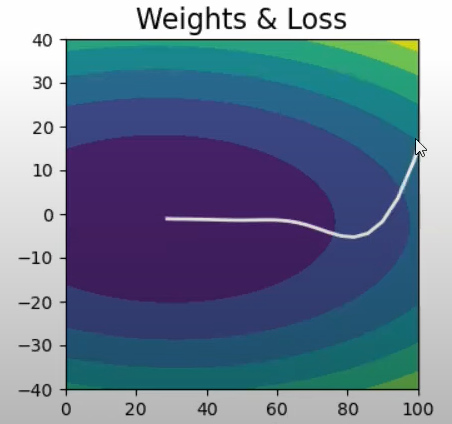
Mathematical representation:
We first calculate the accumulated gradient using the formula
: is the initial learning rate : is the accumulated squared gradients : is a small value (usually around ) : is the gradient at the current step This term helps in adjusting the learning parameters effectively. The parameters which have a large accumulated gradient will have a slower learning rate, and the ones which have a smaller will have a larger learning rate is a small value placed to prevent the denominator from becoming zero in case is 0.
In order to elaborate the intuition, we can imagine a loss function in a two-dimensional space, where the gradient of the loss function increases very weakly in one direction and very strongly in the other direction.
If we now sum up the gradients along the axis in which the gradients increase weakly, the squared sum of these gradients becomes very small. Here the learning rate will be very high adn the weight update will be high too. For the other axis, where the gradients increase sharply, the exact opposite is true.
Hence, we speed up the updating process along the axis with weak gradients by increasing these gradients along this axis. Similarly, we slow down the updates of the weights along the axis with large gradients.
In the weak gradient direction → Higher learning rate → Larger updates
In the strong gradient direction → Lower learning rate → Smaller updates
The disadvantage of AdaGrad is that since it accumulates the squared gradients, the denominator in the update rule keeps increasing as training progresses. As a result, the effective learning rate keeps decreasing and after many iterations, updates become very small. Eventually, the model stops learning, which in many cases may be before reaching the desired global minima and hence cant converge to the desired solution. However, this problem is seen mostly in deep neural network problems only. AdaGrad works efficiently for linear regression models.
RMSProp (Root Mean Square Propagation)
The main disadvantage of AdaGrad optimizer occurs because we consider the values of "all" the past gradients (
RMSProp adapts the learning rate by introducing a moving average of the squared gradients. i.e, The accumulated gradient (
This ensures that the updates are properly scaled for each parameters and prevents the learning rate from becoming too small.
Mathematical representation:
The only change we made from the AdaGrad optimizer is in calculating the velocity term. The second equation remains the same.
RMSProp maintains an optimal learning rate by using a decay rate parameter and hence ensures faster convergence to the desired minima. It is one of the most widely used and efficient optimization algorithm with negligible disadvantages.
Adam
Adam stands for Adaptive Moment Estimation. This method was designed to make the optimization process even faster by combining the logics behind SGD with momentum and Adagrad.
Mathematical representation:
Weight update:
Momentum (First Moment Estimate)
Exponentially weighted average of the past gradients
Variance (Second Moment Estimate):
This term maintains an adaptive learning constant, ensuring that the past gradients have lesser weightage than the current gradients.
Bias Correction:
We require a bias correction because both momentum term and variance are initially zero and are biased towards 0 at during the start of the training