Appearance
LLEs for those in a hurry
by Nikhil R, on 06/02/2025
Introduction
Locally Linear Embedding (LLE), an instance of classical unsupervised manifold learning, aims to uncover low-dimensional representations of high dimensional data while preserving local geometric relationships through the intuitive principle that a large number of points and their neighbours sampled from a smooth underlying manifold lie on or around a locally linear patch. A global embedding is computed through minimization of a sum-of-squares cost function, first on local reconstructions of each point, and then on the target embeddings. When compared with traditional dimensionality reduction techniques such as Principal Component Analysis (PCA), LLE is more effective at capturing complex, nonlinear structures- lending itself amenable to applications in image processing and pattern recognition.
Notation
In this article, for any matrix
Construction
Proposition 3.1. A Gradient Identity
Suppose
Proof: Let
Remark: The matrix identity
Definition 3.1: Reconstruction
A vector
Proposition 3.2.
Consider vector
when
Proof: Consider the variable vector
Remark: The invertibility of
Definition 3.2: k-NN Graph
The k-NN Graph for a set of points
- Let vertices of the graph be
. - Let
be the array of indices such that is the index of the vector that is the k-th nearest neighbour of . - For each
compute , then add an edge from to for with weight
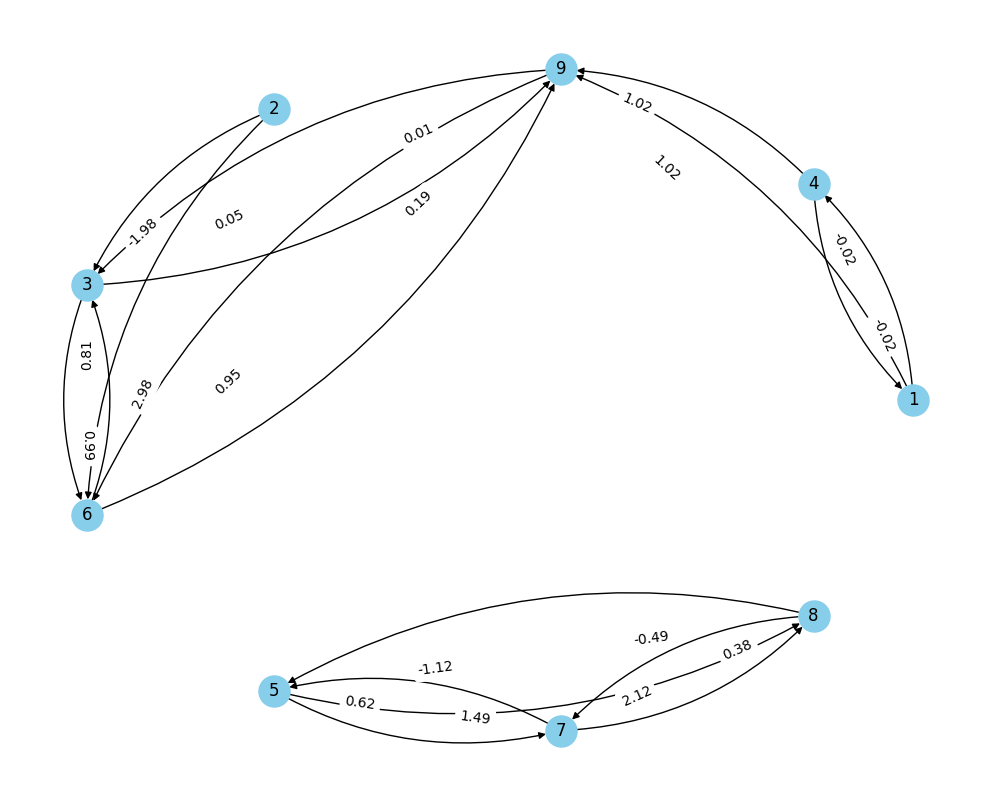
Definition 3.3: Embedding points
The points
Proposition 3.3
The columns of
Proof: Since
Remark: The matrix
Definition 3.4: Out-of-Sample Embedding
The embedding of a vector